Download the data set
By downloading the data set you agree to the license
One Million Posts Corpus
A Data Set of German Online Discussions
This is the home of the “One Million Posts” corpus, an annotated data set consisting of user comments posted to an Austrian newspaper website (in German language).
This data set was presented as a short paper at the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2017). See the Citation section below.
Futhermore, a follow-up paper using this data set was presented in the industry track at the 11th International Conference on Language Resources and Evaluation (LREC 2018). See the Citation section below.
Data Set Description
DER STANDARD is an Austrian daily broadsheet newspaper. On the newspaper’s website, there is a discussion section below each news article where readers engage in online discussions. The data set contains a selection of user posts from the 12 month time span from 2015-06-01 to 2016-05-31. There are 11,773 labeled and 1,000,000 unlabeled posts in the data set. The labeled posts were annotated by professional forum moderators employed by the newspaper.
The data set contains the following data for each post:
- Post ID
- Article ID
- Headline (max. 250 characters)
- Main Body (max. 750 characters)
- User ID (the user names used by the website have been re-mapped to new numeric IDs)
- Time stamp
- Parent post (replies give rise to tree-like discussion thread structures)
- Status (online or deleted by a moderator)
- Number of positive votes by other community members
- Number of negative votes by other community members
For each article, the data set contains the following data:
- Article ID
- Publishing date
- Topic Path (e.g.: Newsroom / Sports / Motorsports / Formula 1)
- Title
- Body
The data is provided in the form of an SQLite database file. See also the commented database schema.
Detailed descriptions of the post selection and annotation procedures are given in the paper.
Annotated Categories
Potentially undesirable content:
- Sentiment (negative/neutral/positive)
An important goal is to detect changes in the prevalent sentiment in a discussion, e.g., the location within the fora and the point in time where a turn from positive/neutral sentiment to negative sentiment takes place. - Off-Topic (yes/no)
Posts which digress too far from the topic of the corresponding article. - Inappropriate (yes/no)
Swearwords, suggestive and obscene language, insults, threats etc. - Discriminating (yes/no)
Racist, sexist, misogynistic, homophobic, antisemitic and other misanthropic content.
Neutral content that requires a reaction:
- Feedback (yes/no)
Sometimes users ask questions or give feedback to the author of the article or the newspaper in general, which may require a reply/reaction.
Potentially desirable content:
- Personal Stories (yes/no)
In certain fora, users are encouraged to share their personal stories, experiences, anecdotes etc. regarding the respective topic. - Arguments Used (yes/no)
It is desirable for users to back their statements with rational argumentation, reasoning and sources.
Several of these categories are based on respective rules in the community guidelines of the website.
Statistics
The following table contains some relevant statistics for the data set.
| Total number of posts | 1,011,773 |
| Number of unlabeled posts | 1,000,000 |
| Number of labeled posts | 11,773 |
| Number of category annotation decisions | 58,568 |
| Number of posts taken offline by moderators | 62,320 |
| Min/Median/Max post length (words) | 0 / 21 / 500 |
| Vocabulary size (≥ 5 occurrences) | 129,070 |
| Number of articles | 12,087 |
| Number of article topics | 1,229 |
| Number of users | 31,413 |
| Min/Median/Max number of posts per article | 1 / 22 / 3,656 |
| Min/Median/Max number of posts per topic | 1 / 142 / 44,329 |
| Min/Median/Max number of posts per user | 1 / 5 / 4,682 |
| Min/Median/Max number of users per article | 1 / 15 / 1,371 |
| Min/Median/Max number of users per topic | 1 / 78 / 6,874 |
| Number of pos./neg. community votes | 3,824,806 / 1,096,300 |
The following table gives the number of labeled examples per category.
| Category | Does Apply | Does Not Apply | Total | Percentage |
|---|---|---|---|---|
| Sentiment Negative | 1691 | 1908 | 3599 | 47 % |
| Sentiment Neutral | 1865 | 1734 | 3599 | 52 % |
| Sentiment Positive | 43 | 3556 | 3599 | 1 % |
| Off-Topic | 580 | 3019 | 3599 | 16 % |
| Inappropriate | 303 | 3296 | 3599 | 8 % |
| Discriminating | 282 | 3317 | 3599 | 8 % |
| Possibly Feedback | 1301 | 4737 | 6038 | 22 % |
| Personal Stories | 1625 | 7711 | 9336 | 17 % |
| Arguments Used | 1022 | 2577 | 3599 | 28 % |
In the first annotation round, three moderators annotated 1,000 randomly selected posts. From this subset of the data, we can estimate the category distributions. The following bar chart shows the distribution for the three annotators (A, B, C) and after a majority vote per post.
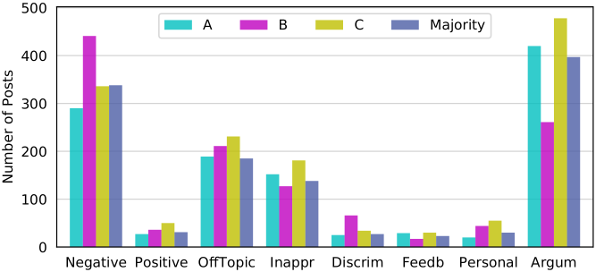
Furthermore, this subset can be used to compute Cohen’s Kappa values to quantify the inter-rater agreement. The following bar chart shows the agreement for each pair of moderators and the average across all pairs for each category.
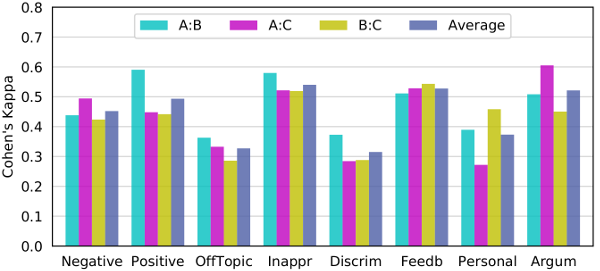
The distribution of posts to topic paths is illustrated below (regular scale on the left, log scale on the right).
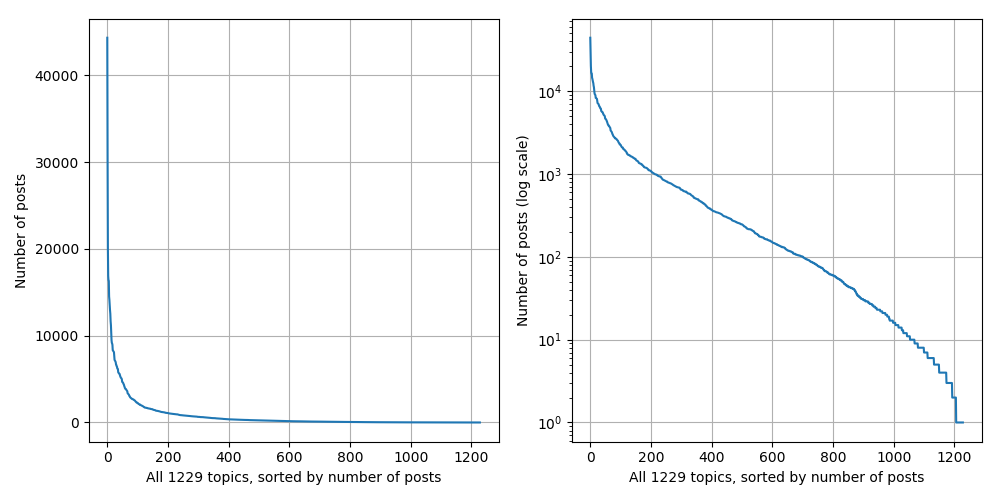
The 10 topic paths with the most posts are listed below (see the top 100 here). Topics from the selected time window (2015-06-01 to 2016-05-31) with broad general interest show up, like the European migrant crisis, the 2016 Austrian presidential elections and the Syrian Civil War.
| Posts | Topic Path |
|---|---|
| 44,329 | Newsroom/Panorama/Flucht/Fluechtlinge_in_Oesterreich |
| 30,604 | Newsroom/Panorama/Flucht/Flucht_und_Politik |
| 20,177 | Newsroom/Inland/bundespraesi |
| 16,896 | Newsroom/International/Nahost/syrien |
| 16,362 | Newsroom/Panorama/Weltchronik |
| 16,334 | Newsroom/Panorama/Chronik |
| 14,516 | Newsroom/Web/Netzpolitik |
| 14,112 | Newsroom/Web/Netzpolitik/Hasspostings |
| 13,463 | Newsroom/Wirtschaft/Wirtschaftpolitik/Finanzmaerkte/Griechenlandkrise |
| 12,951 | Newsroom/Inland/Parteien/fp |
The top 10 category paths with respect to category prevalence are given in category_per_topic.md
License
This data set is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.

Citation
The data set was first presented at SIGIR 2017:
Dietmar Schabus, Marcin Skowron, Martin Trapp
One Million Posts: A Data Set of German Online Discussions
Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR)
pp. 1241-1244
Tokyo, Japan, August 2017
Please cite this paper if you use the data set (BibTeX below). You can download a preprint version of the paper here. The definitive version of the paper is available under DOI 10.1145/3077136.3080711.
@InProceedings{Schabus2017,
Author = {Dietmar Schabus and Marcin Skowron and Martin Trapp},
Title = {One Million Posts: A Data Set of German Online Discussions},
Booktitle = {Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR)},
Pages = {1241--1244},
Year = {2017},
Address = {Tokyo, Japan},
Doi = {10.1145/3077136.3080711},
Month = aug
}
Furthermore, this data set was used in a follow-up paper presented at LREC 2018:
Dietmar Schabus and Marcin Skowron
Academic-Industrial Perspective on the Development and Deployment of a Moderation System for a Newspaper Website
Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC 2018)
pp. 1602-1605
Miyazaki, Japan, May 2018
Full paper available for download from LREC.
@InProceedings{Schabus2018,
author = {Dietmar Schabus and Marcin Skowron},
title = {Academic-Industrial Perspective on the Development and Deployment of a Moderation System for a Newspaper Website},
booktitle = {Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC)},
year = {2018},
address = {Miyazaki, Japan},
month = may,
pages = {1602-1605},
abstract = {This paper describes an approach and our experiences from the development, deployment and usability testing of a Natural Language Processing (NLP) and Information Retrieval system that supports the moderation of user comments on a large newspaper website. We highlight some of the differences between industry-oriented and academic research settings and their influence on the decisions made in the data collection and annotation processes, selection of document representation and machine learning methods. We report on classification results, where the problems to solve and the data to work with come from a commercial enterprise. In this context typical for NLP research, we discuss relevant industrial aspects. We believe that the challenges faced as well as the solutions proposed for addressing them can provide insights to others working in a similar setting.},
url = {http://www.lrec-conf.org/proceedings/lrec2018/summaries/8885.html},
}
Experiments
The code and instructions to reproduce the experimental results presented in the paper can be found in the experiments folder in the GitHub repository.
Acknowledgments
This research was partially funded by the Google Digital News Initiative. We thank DER STANDARD and their moderators for the interesting collaboration and the annotation of the presented corpus. The GPU used for this research was donated by NVIDIA.